We need to give LLMs human-like vision
Most people think that the biggest problem facing LLMs is continuous learning.
The far bigger problem in my opinion is that LLMs cannot use the most important interface humans have - a keyboard and mouse.
How can LLMs program websites without being able to FEEL the scrolling animation? How will they use a computer, beat the game Montezuma's Revenge*, or more generally, pass the Turing test, if they can’t even move the mouse smoothly?
Some people think that we can give LLMs human-like perception by feeding screenshots into the context window every few seconds, but it is obvious to me that infinite context will (and already does) cause this to fail miserably.
Infinite context is a hack, and I think we should stop working on it. I can't go more than a few messages with GPT-5 or Claude Sonnet 4.5 without the context window filling up, and my costs 10x-ing. Images and videos will only make the problem worse. Here are some other massive flaws to infinite context:
- Low information density due to persisting entire files, images, and basically everything the model has ever seen. Test-time compute increases signal-to-noise, but persisting any raw text files and images will detract almost all benefits. And Deepseek's compression work is not ideal because it is lossy.
- Using O(n) energy. It would be laughable if you became more and more exhausted as you read this blog post.
- Having to synchronously pause to take actions.
The "problem behind the problem" of infinite context is that LLMs have no sense of time - as mentioned above, LLMs cannot interact with anything without synchronously pausing. Even if we could allow LLMs to interact with the world around them in a not obviously bad way, any audio or video tokens would quickly fill the context window up and remove all benefits.
One solution is to make the first thousand tokens store information about what is happening at the current moment in time. These tokens tell you the current inputs, like “what is the LLM currently looking at?". They can also express the current action, like "what buttons are the LLM currently pressing?". These tokens are replaced at every moment in time, analogous to how if a human looks around a room, the previous image they were looking at is replaced with the current one.
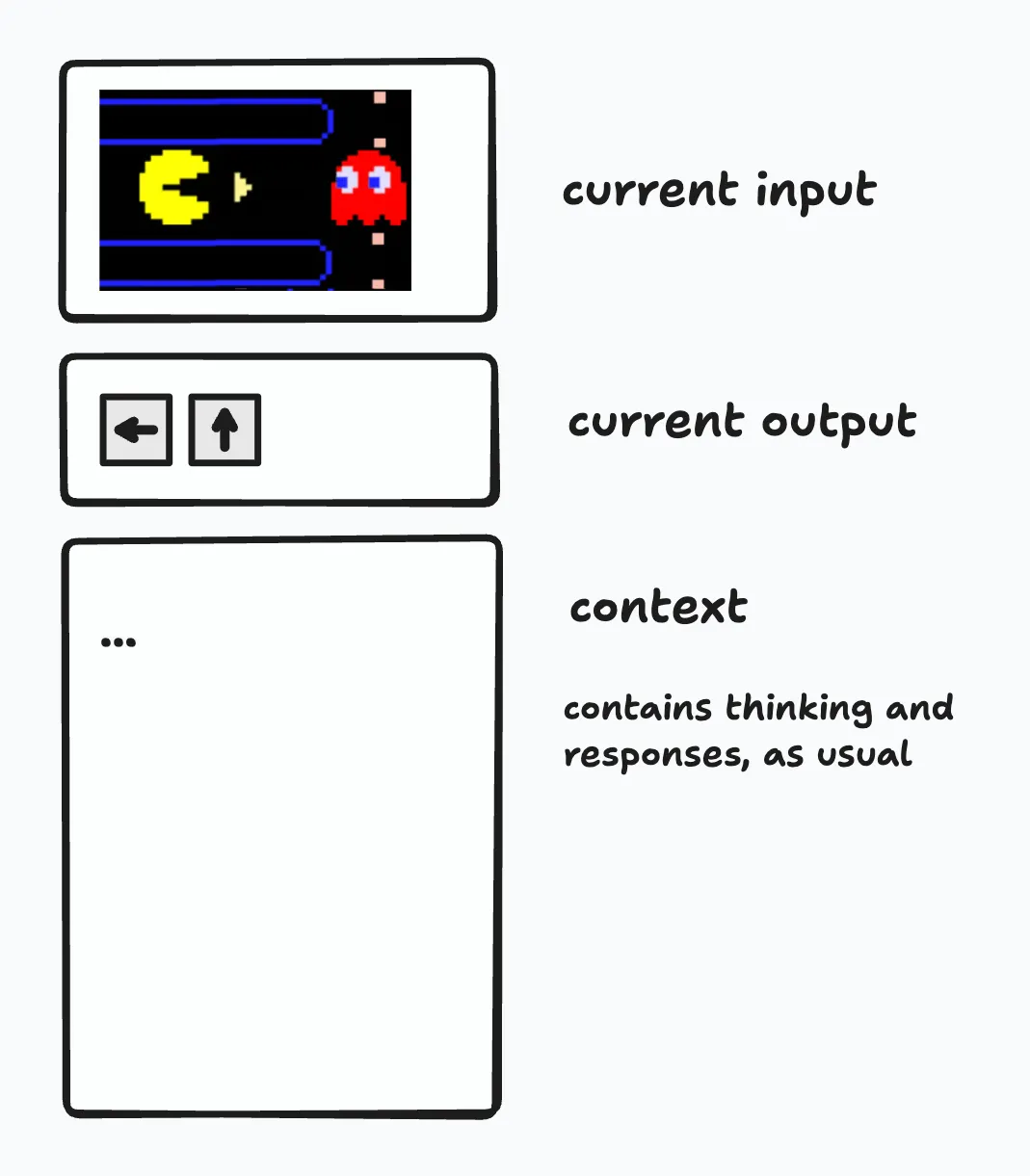
Fig 1: Architecture of an LLM with a continuous-time stream of inputs and outputs. We introduce "current input" and "current output" tokens, which are stored at the top of the context window and overwritten after every forward pass. The current output is found by parsing any
This architecture is much more "human" as most of the context window is high-signal thinking tokens. The only low-signal tokens are the current tokens, which are a small and fixed portion of the context window at the very top.
Some benefits of a human-like input and output stream:
- LLMs will be able to complete every keyboard-and-mouse task that humans can do with a tight ~100ms feedback loop.
- Large benefits for AI coding, as the context window never persists raw files or code and will fill much more slowly.
If you are a large lab working on this and think I can help, please email me at matml.anon@gmail.com. I have some early results and they are promising. I'm also generally open to any thoughts on the architecture. I'll be scaling up training in the next week or two.